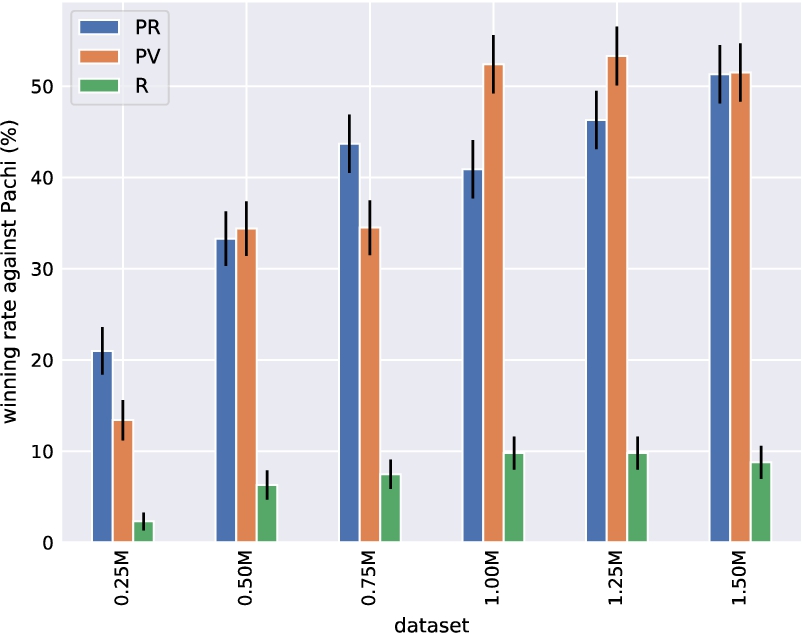
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Por um escritor misterioso
Descrição

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
RankNet for evaluation functions of the game of Go - IOS Press

Student of Games: A unified learning algorithm for both perfect and imperfect information games
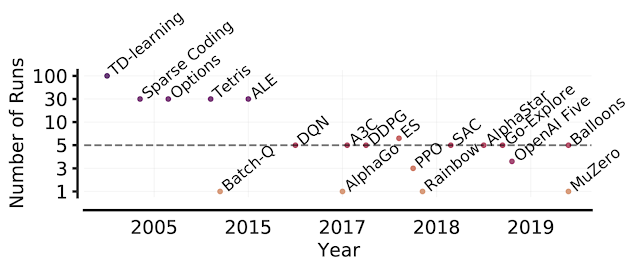
RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning – Google Research Blog

Is AlphaGo Really Such a Big Deal?

Empirical evaluation of AlphaGo Zero. a Performance of self-play
Applied Sciences, Free Full-Text

Diversifying AI: DeepMind Pushes AI Toward Creative Game Players

Student of Games: A unified learning algorithm for both perfect and imperfect information games

Student of Games: A unified learning algorithm for both perfect and imperfect information games
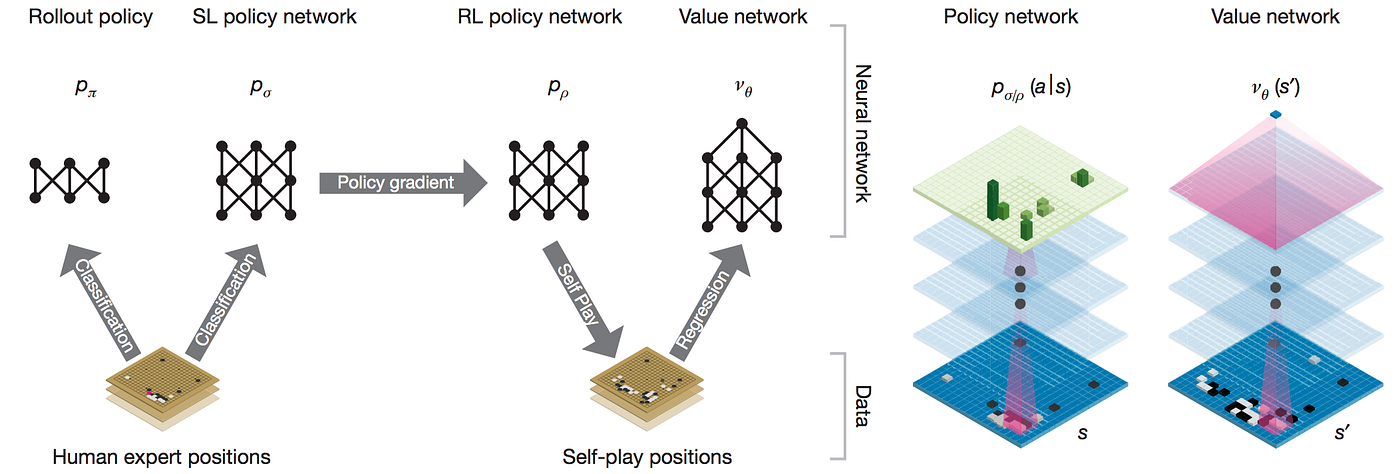
AlphaGo, in context. Update Oct 18, 2017: AlphaGo Zero was…, by Andrej Karpathy
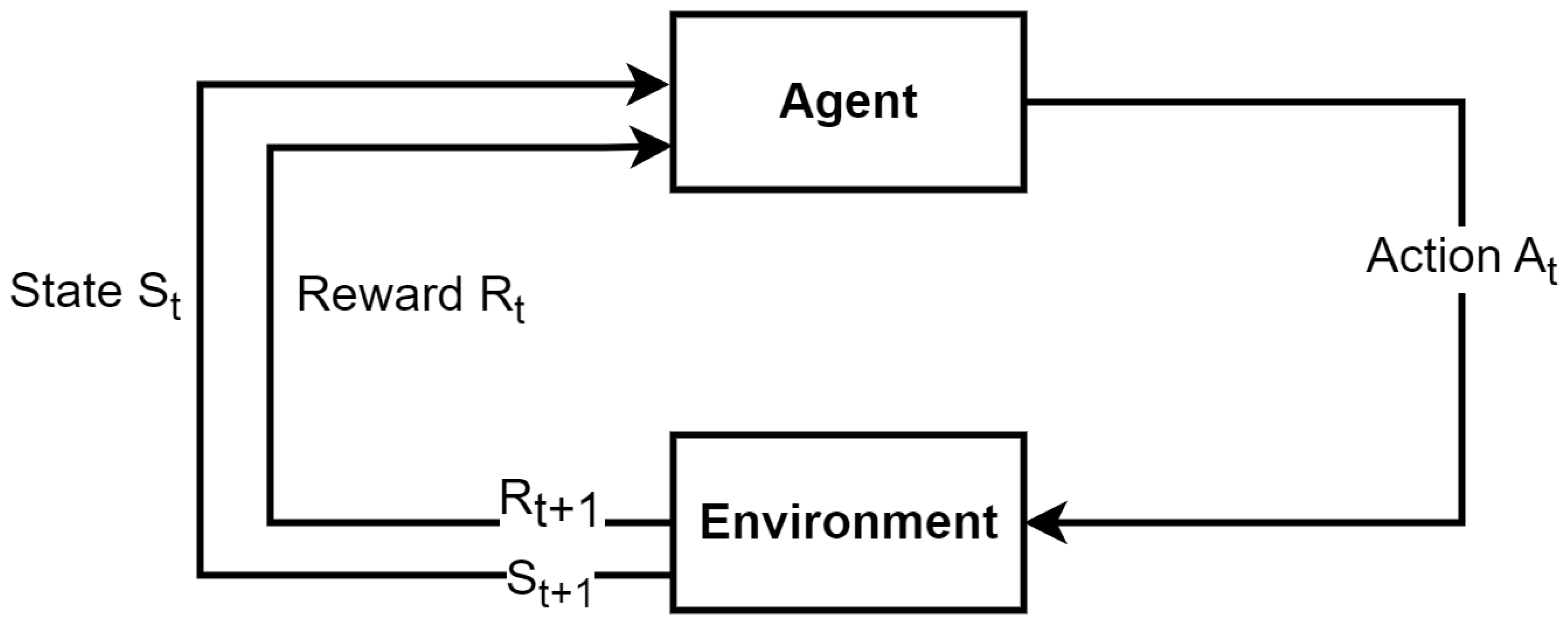
Self-play reinforcement learning in AlphaGo Zero. a The program plays a
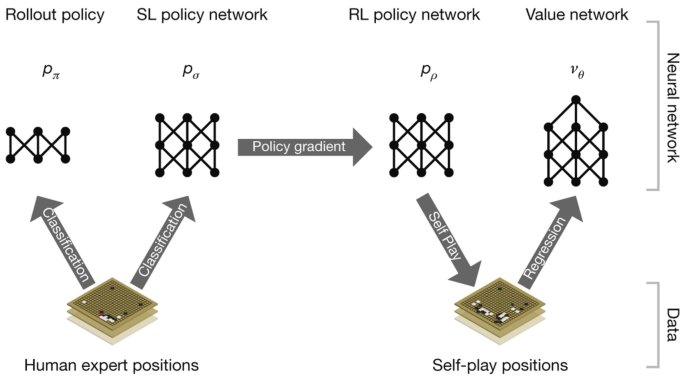
Two-Agent Self-Play
de
por adulto (o preço varia de acordo com o tamanho do grupo)