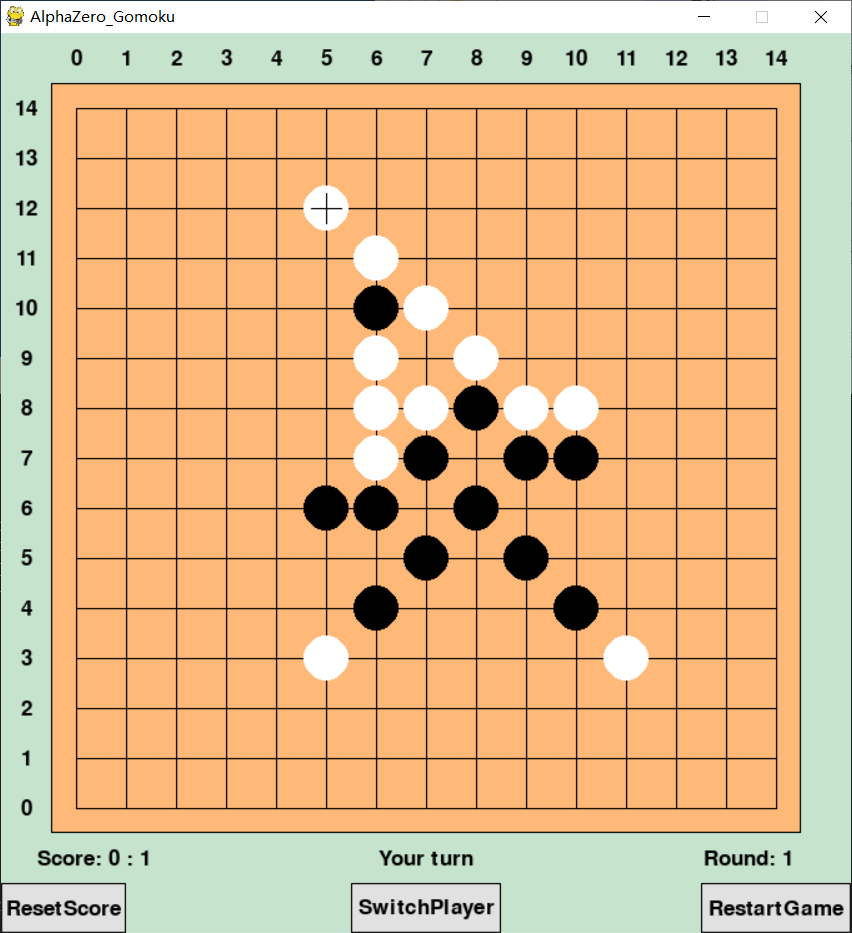
The average number of unique states visited by AlphaZero and Go-Exploit
Por um escritor misterioso
Descrição
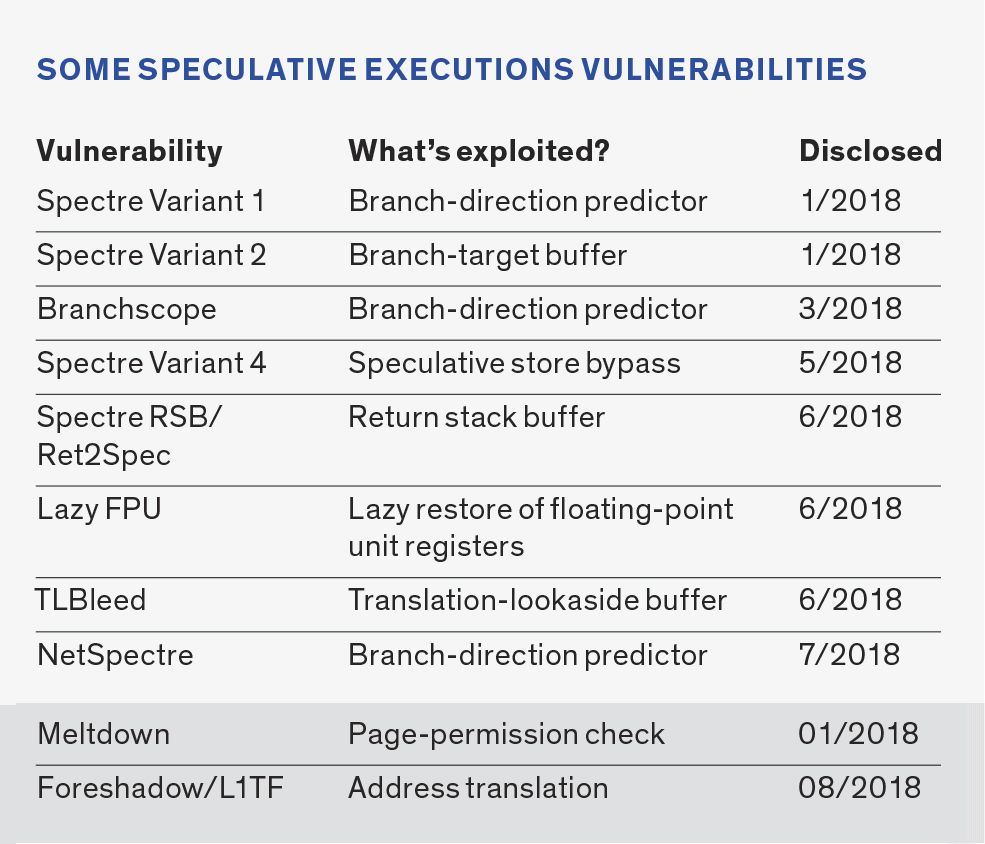
How the Spectre and Meltdown Hacks Really Worked
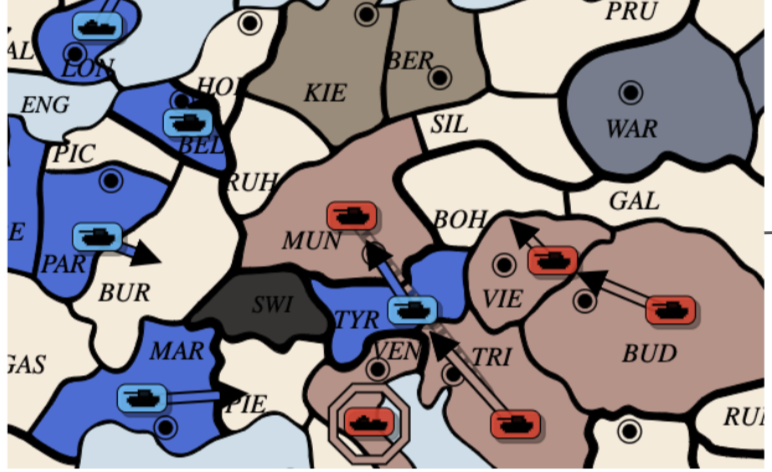
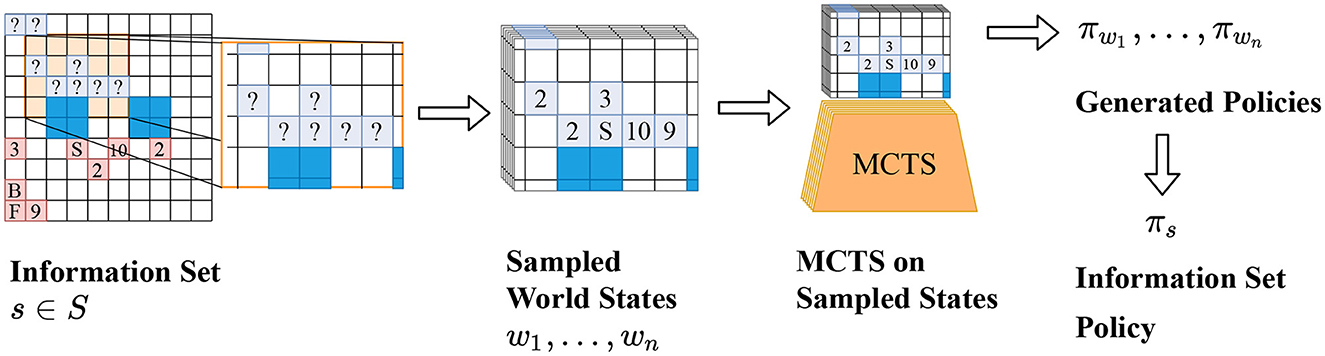
2110.02924] No-Press Diplomacy from Scratch

Lecture 13: Reinforcement learning
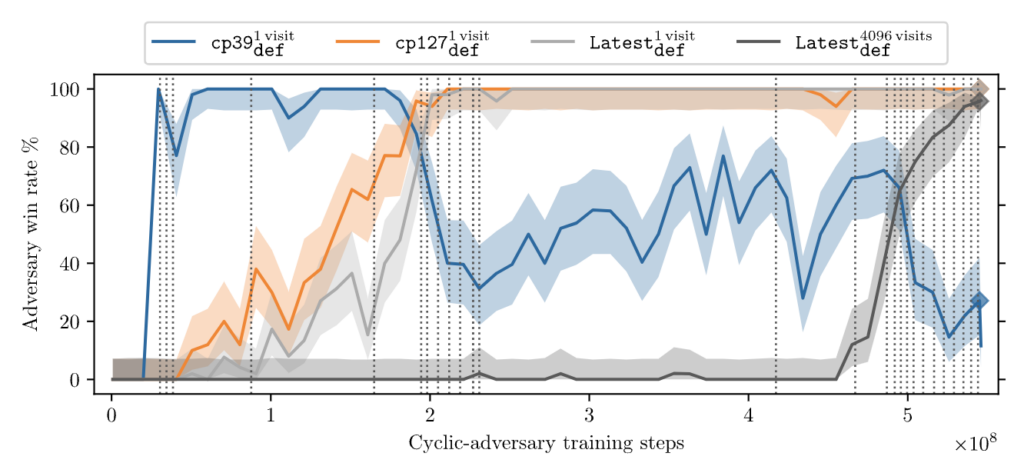
Even Superhuman Go AIs Have Surprising Failures Modes – Center for Human-Compatible Artificial Intelligence

Lecture 13: Reinforcement learning
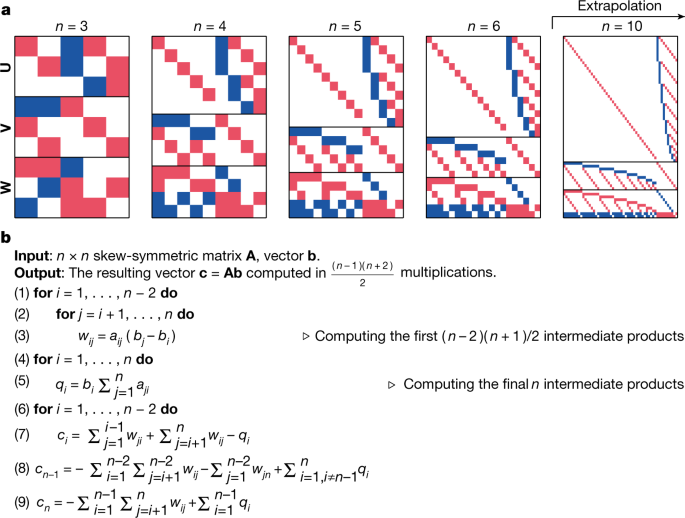
Discovering faster matrix multiplication algorithms with reinforcement learning

Science Magazine - December 7, 2018 - Building two-dimensional materials one row at a time: Avoiding the nucleation barrier
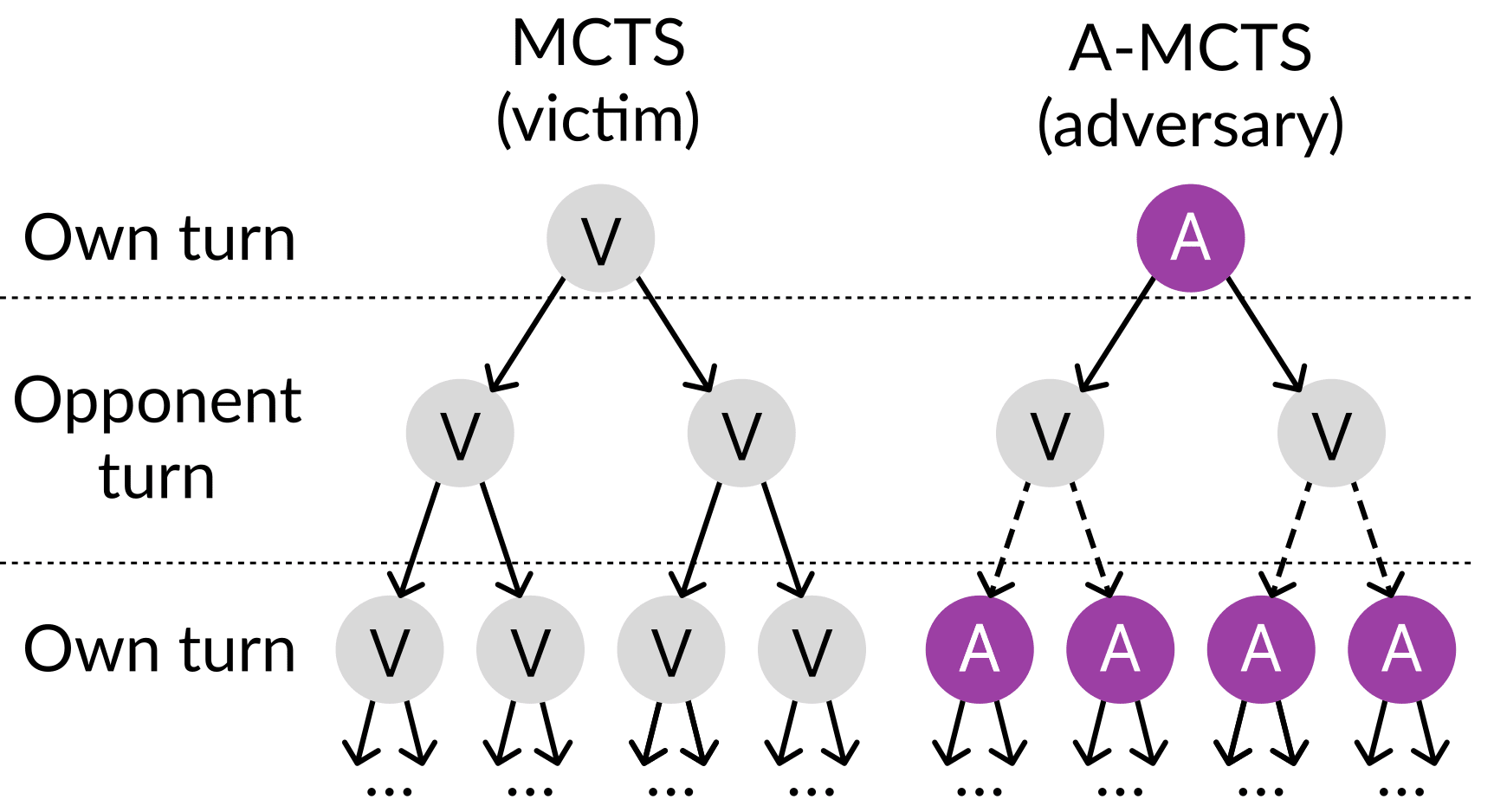
Even Superhuman Go AIs Have Surprising Failure Modes — LessWrong
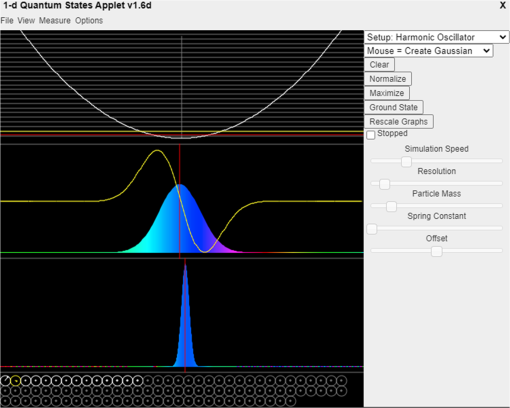
Quantum games and interactive tools for quantum technologies outreach and education

Monte Carlo Tree Search - A Quick Introduction (with Code) - Dilith Jayakody

AlphaGo Zero: Mastering the Game of Go Without Human Knowledge
AlphaZero Explained · On AI
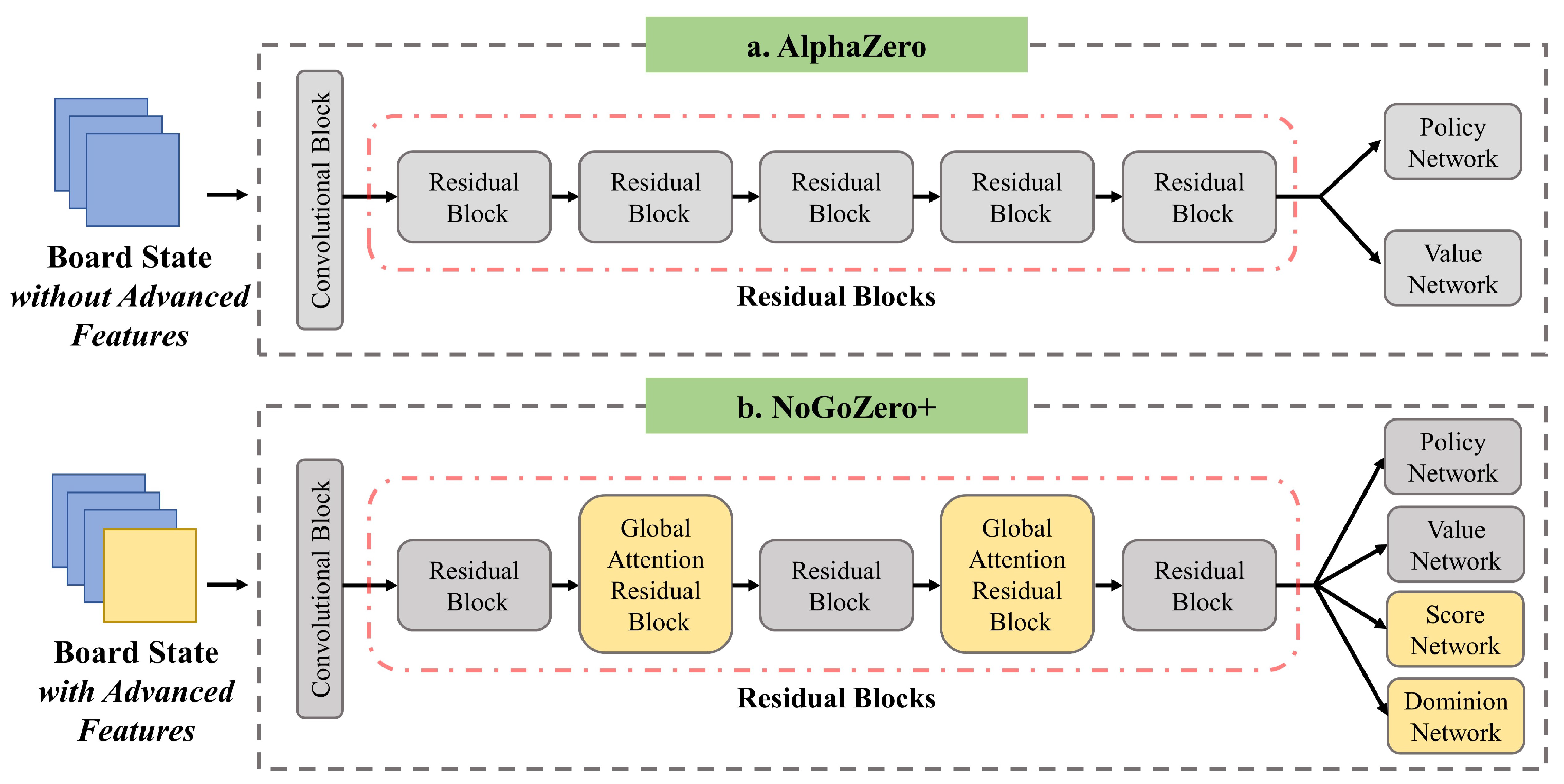
Electronics, Free Full-Text

AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play
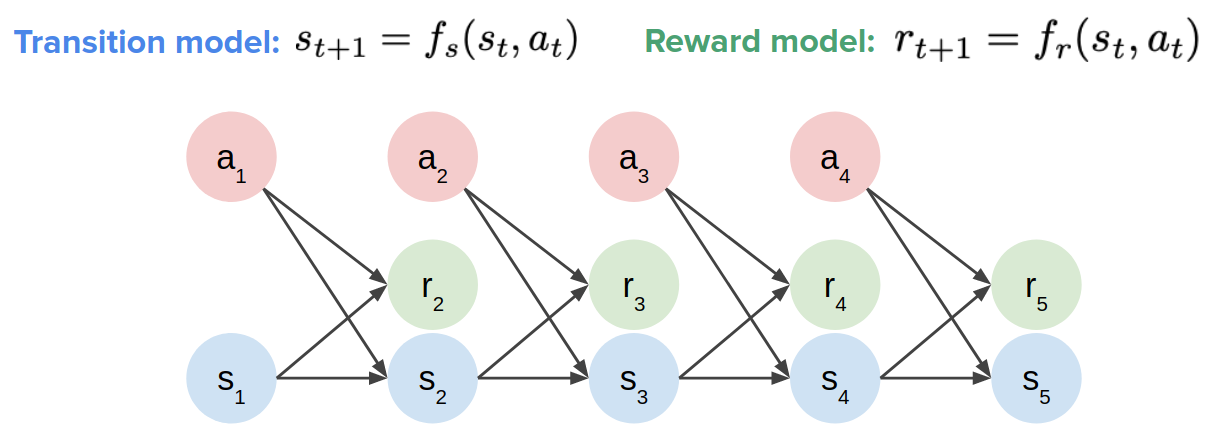
Model-Based Reinforcement Learning (MBRL), by Isaac Kargar
de
por adulto (o preço varia de acordo com o tamanho do grupo)