H100, L4 and Orin Raise the Bar for Inference in MLPerf
Por um escritor misterioso
Descrição
NVIDIA H100 and L4 GPUs took generative AI and all other workloads to new levels in the latest MLPerf benchmarks, while Jetson AGX Orin made performance and efficiency gains.
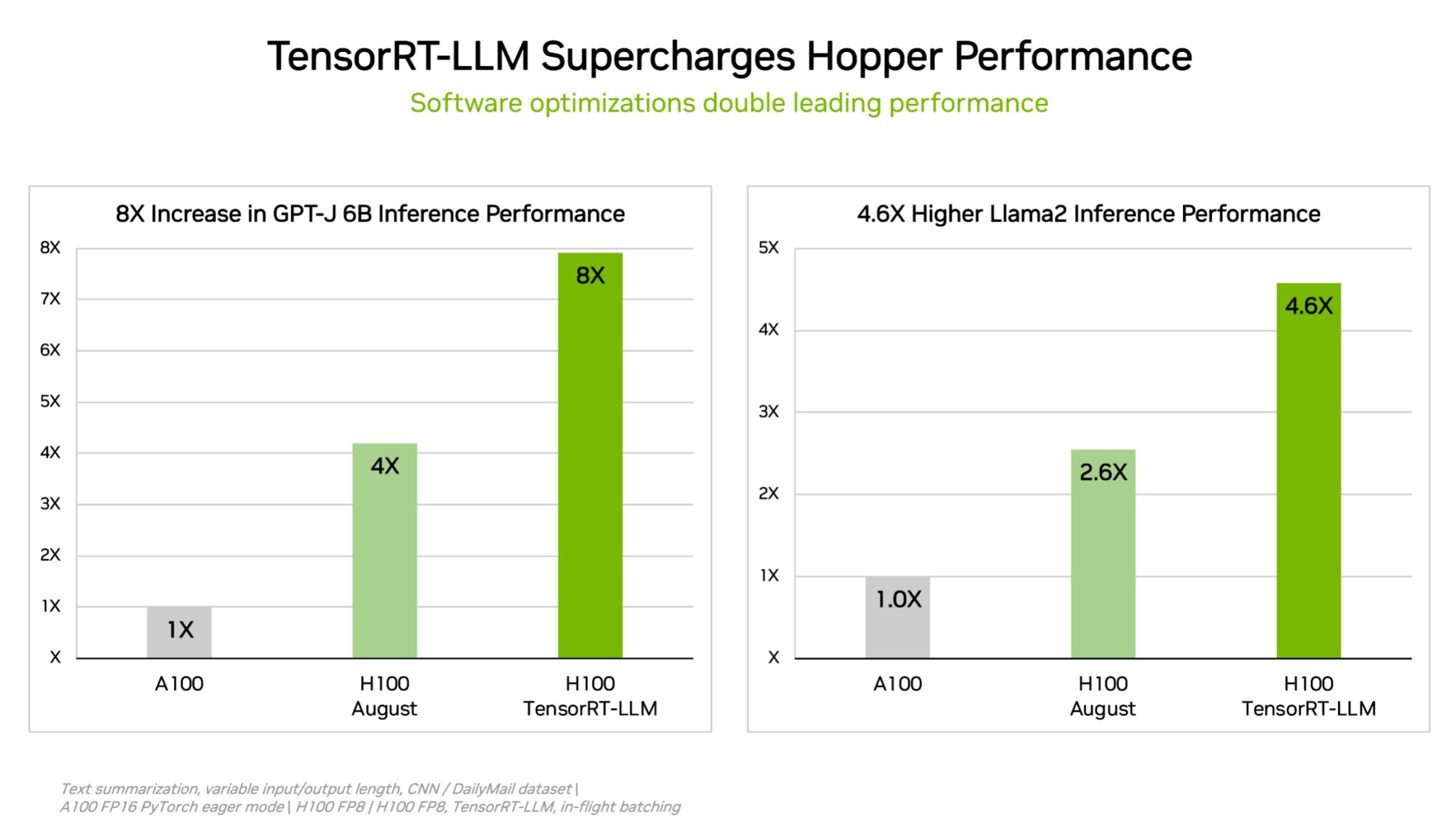
NVIDIA Grace Hopper Superchip Sweeps MLPerf Inference Benchmarks

Aaron Erickson on LinkedIn: NVIDIA Grace Hopper Superchip Sweeps MLPerf Inference Benchmarks

NVIDIA Posts Big AI Numbers In MLPerf Inference v3.1 Benchmarks With Hopper H100, GH200 Superchips & L4 GPUs
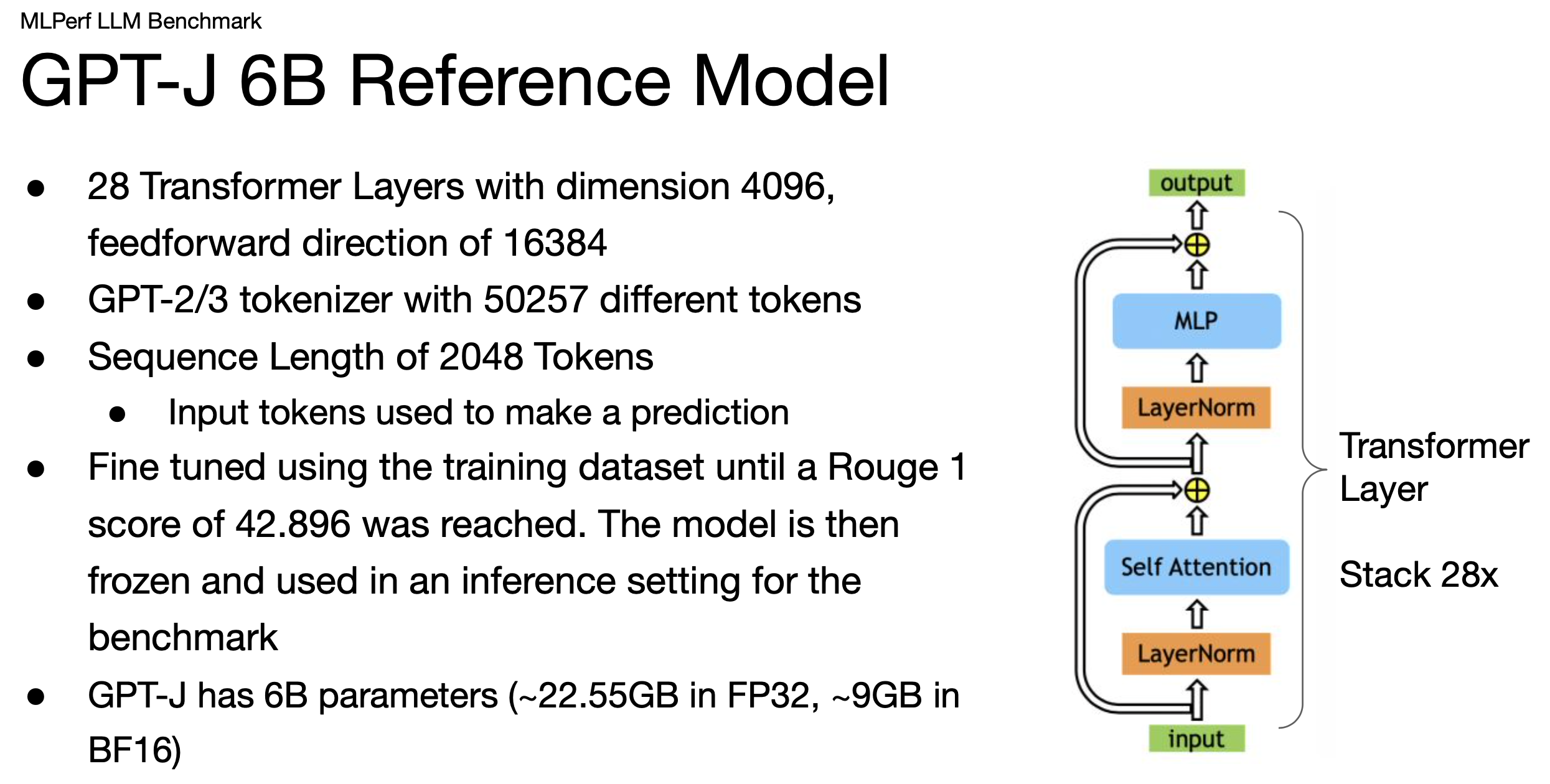
MLPerf Releases Latest Inference Results and New Storage Benchmark
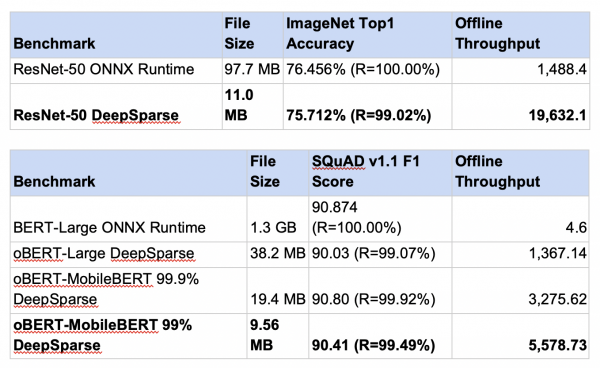
MLPerf Inference 3.0 Highlights - Nvidia, Intel, Qualcomm and…ChatGPT

Google researchers claim that Google's AI processor ``TPU v4'' is faster and more efficient than NVIDIA's ``A100'' - GIGAZINE

MLPerf Inference: Startups Beat Nvidia on Power Efficiency
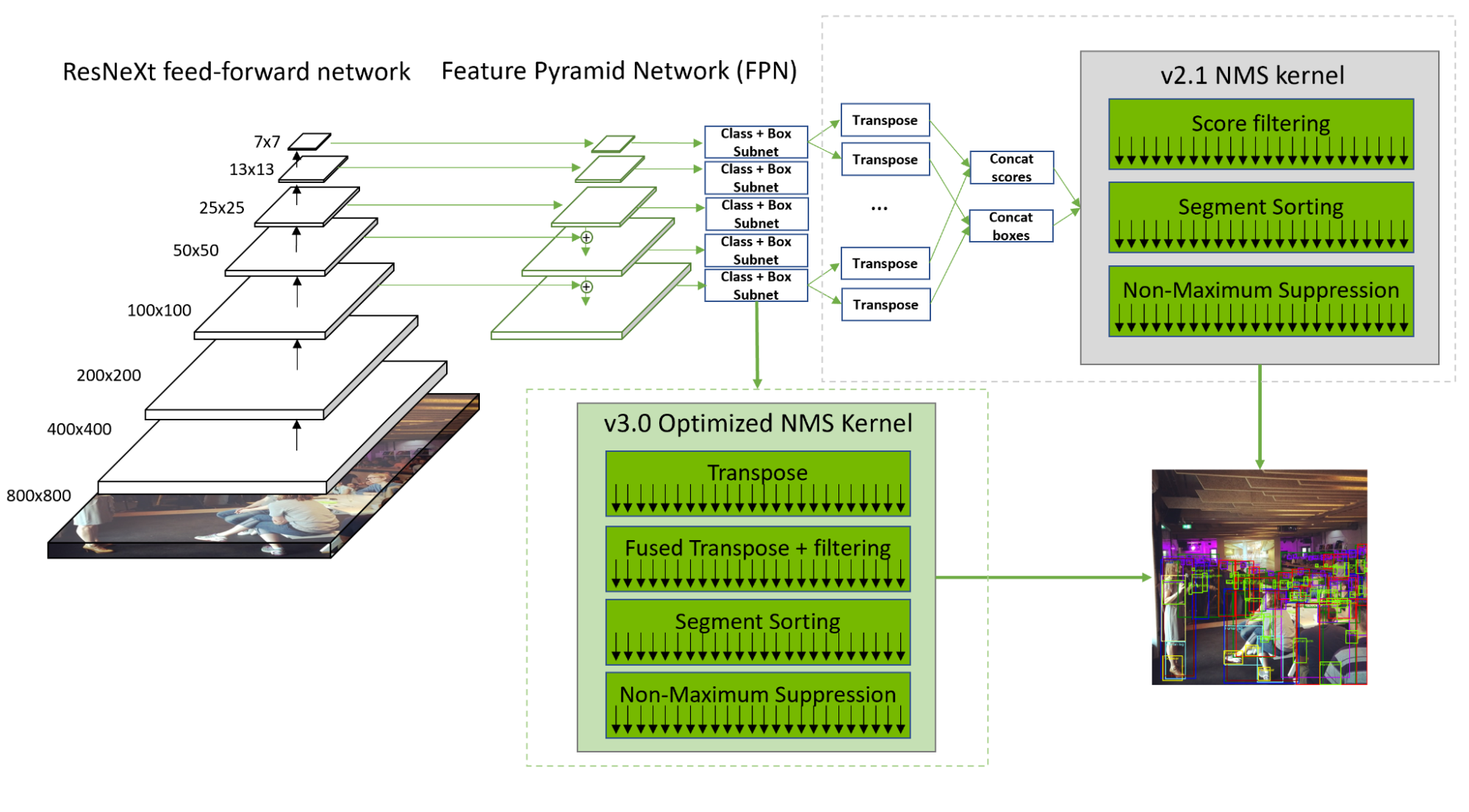
Setting New Records in MLPerf Inference v3.0 with Full-Stack Optimizations for AI

With MLPerf, NVIDIA Wins, AGAIN!

D] LLM inference energy efficiency compared (MLPerf Inference Datacenter v3.0 results) : r/MachineLearning
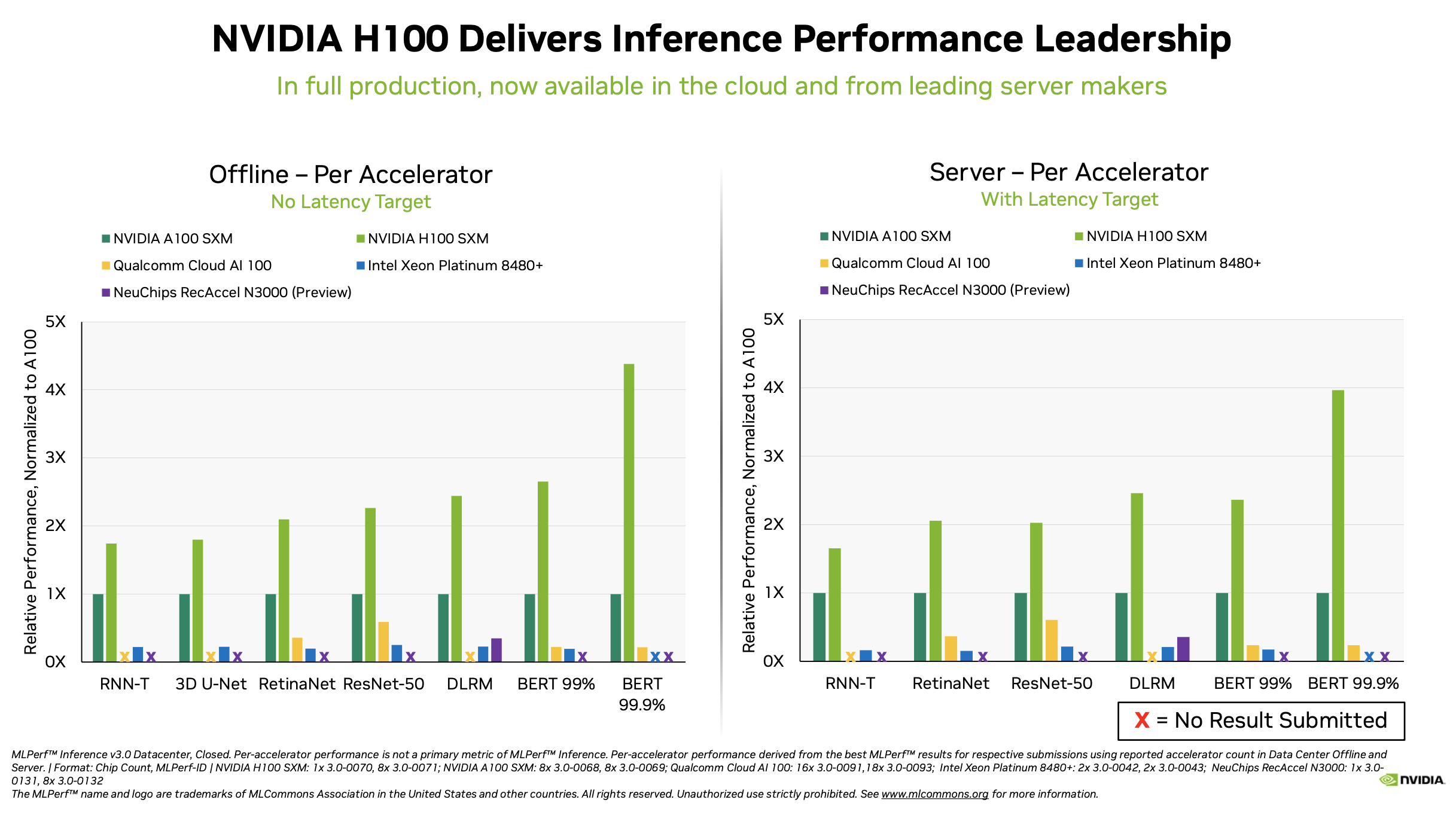
MLPerf Inference 3.0 Highlights - Nvidia, Intel, Qualcomm and…ChatGPT

MLPerf Releases Latest Inference Results and New Storage Benchmark

NVIDIA Posts Big AI Numbers In MLPerf Inference v3.1 Benchmarks With Hopper H100, GH200 Superchips & L4 GPUs
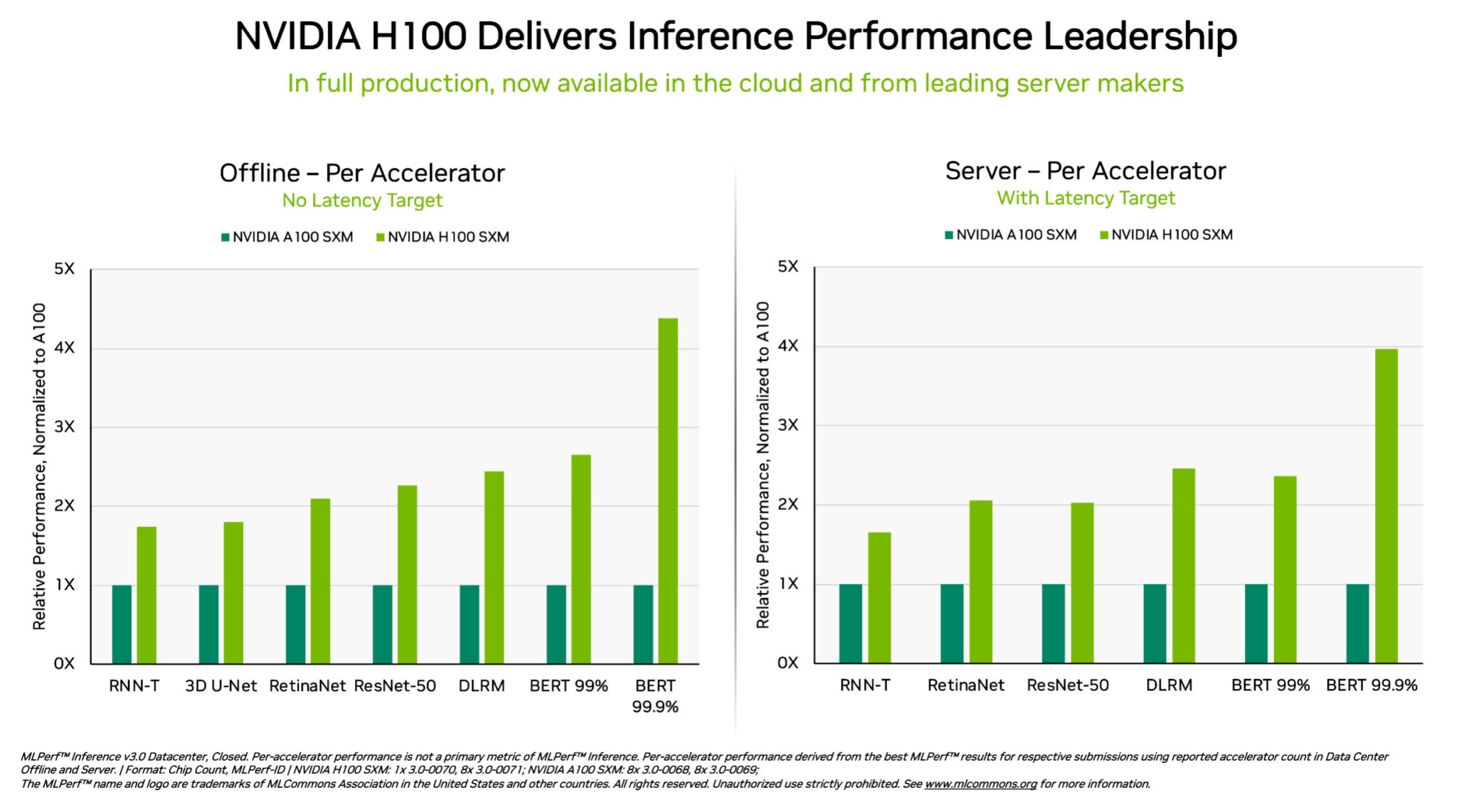
H100, L4 and Orin Raise the Bar for Inference in MLPerf
de
por adulto (o preço varia de acordo com o tamanho do grupo)