From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning
Por um escritor misterioso
Descrição
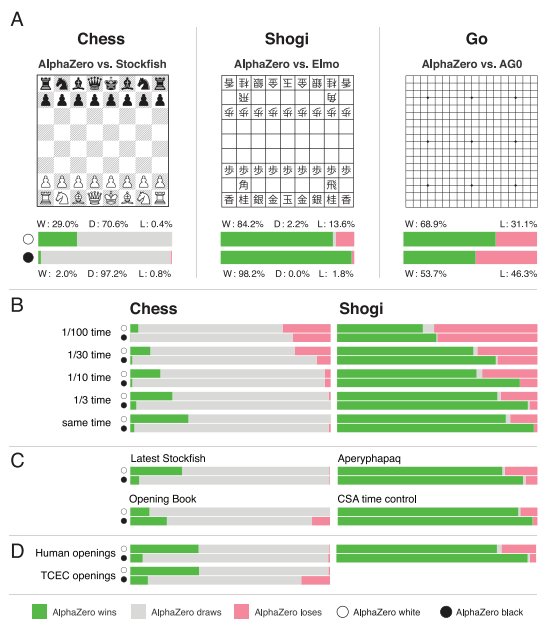
Google’s DeepMind has once again surprised the machine learning community, this time with the introduction of AlphaZero — a new algorithm that can quickly surpass human board game performance through reinforcement learning self-play. It was was just two months that DeepMind published their Nature paper on AlphaGo Zero, which mastered the game of Go in
Mastering the game of Go without human knowledge

Way beyond AlphaZero: Berkeley and Google work shows robotics may be the deepest machine learning of all

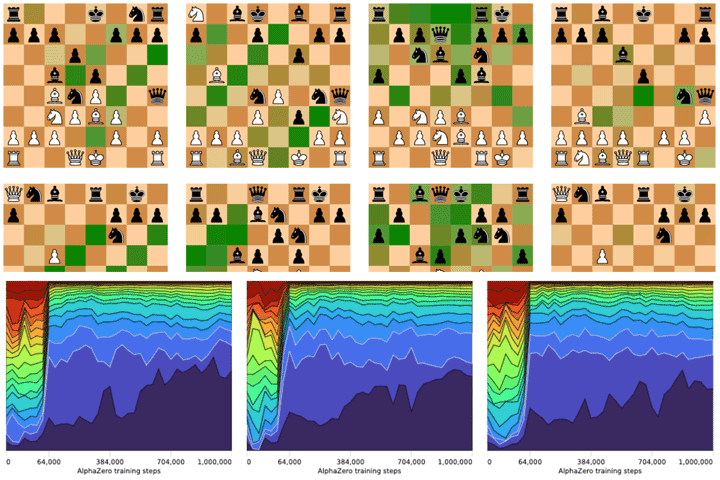
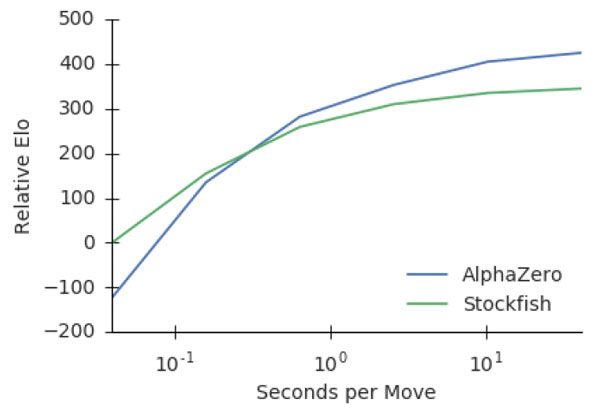
On its own, in just a few hours of experimental self-play, AlphaZero blew past a level of Chess mastery that took humans over 1,500 years to attain., by 13D Research

Diversifying AI: DeepMind Pushes AI Toward Creative Game Players
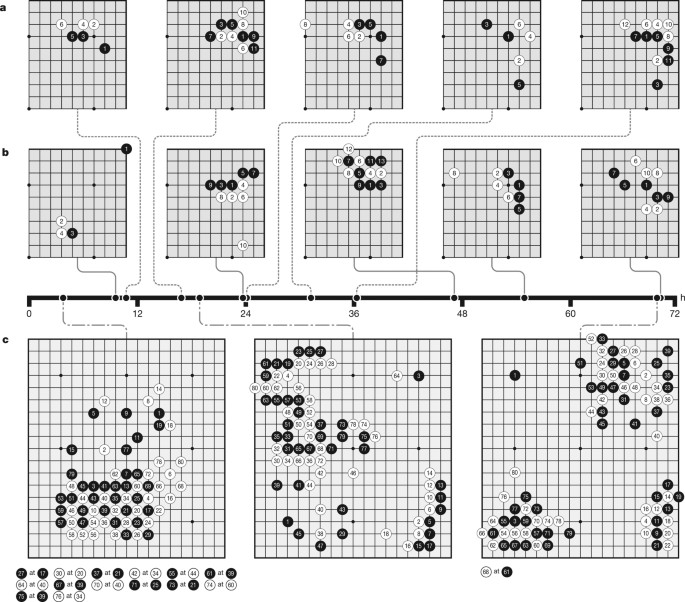
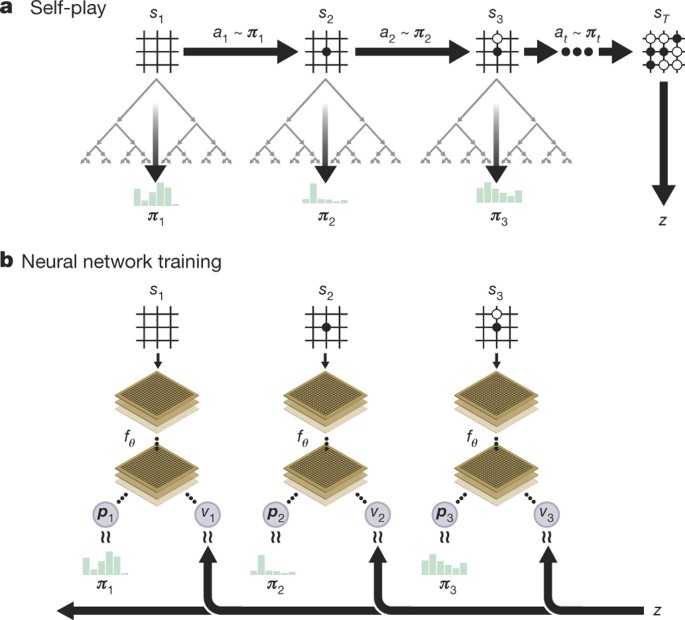
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

Deep learning, reinforcement learning, and world models - ScienceDirect

Reinforcement Learning, Fast and Slow: Trends in Cognitive Sciences
Does AlphaGo Zero threaten data science field since Zero doesn't need big data training and analysis? - Quora
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Mastering the game of Go without human knowledge
de
por adulto (o preço varia de acordo com o tamanho do grupo)