8 Advanced parallelization - Deep Learning with JAX
Por um escritor misterioso
Descrição
Using easy-to-revise parallelism with xmap() · Compiling and automatically partitioning functions with pjit() · Using tensor sharding to achieve parallelization with XLA · Running code in multi-host configurations
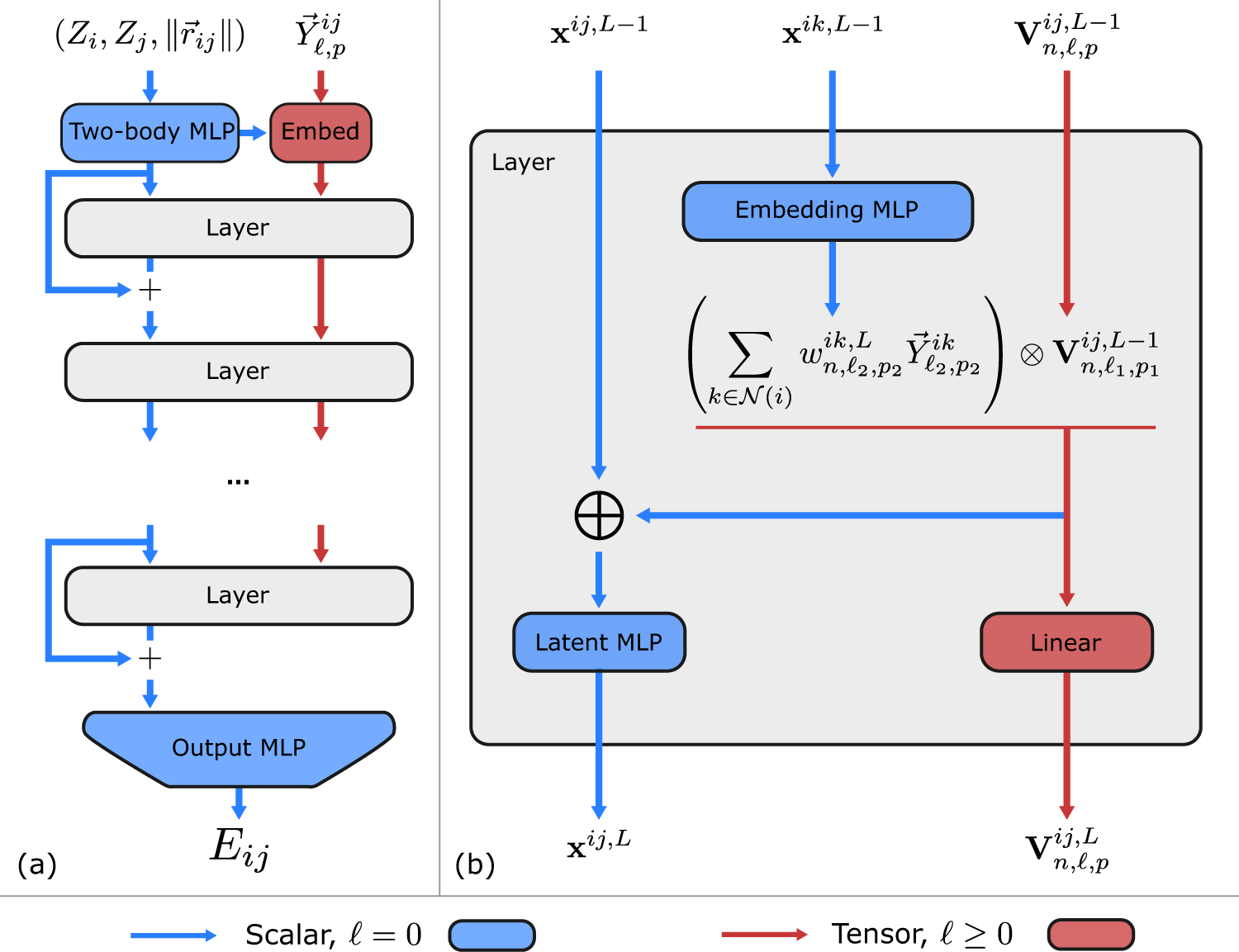
Learning local equivariant representations for large-scale
Learn JAX in 2023: Part 2 - grad, jit, vmap, and pmap
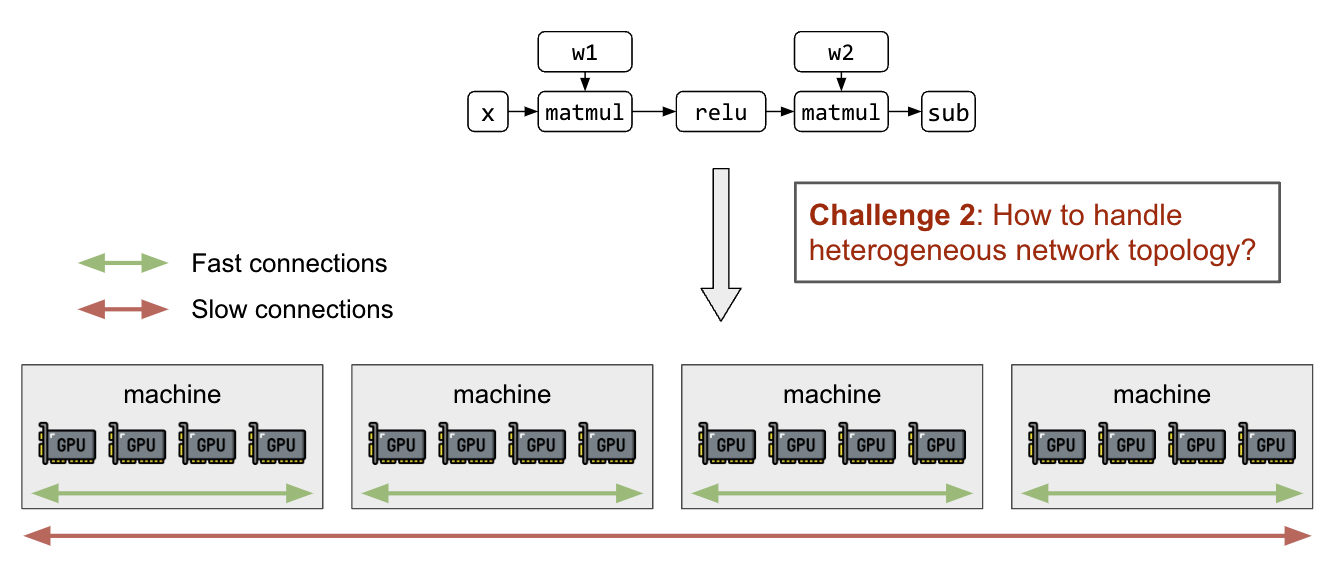
Efficiently Scale LLM Training Across a Large GPU Cluster with

JAX: accelerated machine learning research via composable function
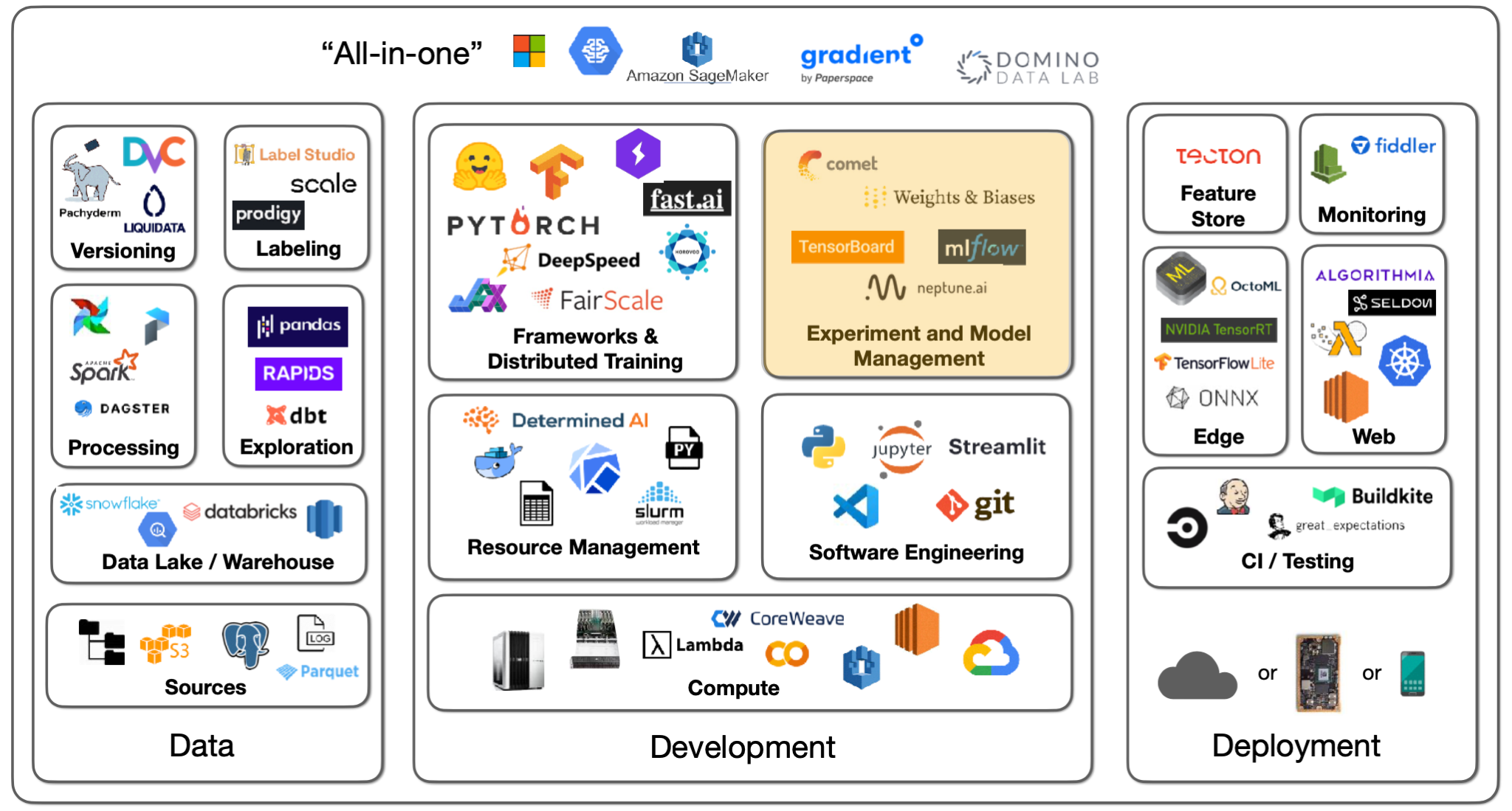
Lecture 2: Development Infrastructure & Tooling - The Full Stack

Learn JAX in 2023: Part 2 - grad, jit, vmap, and pmap
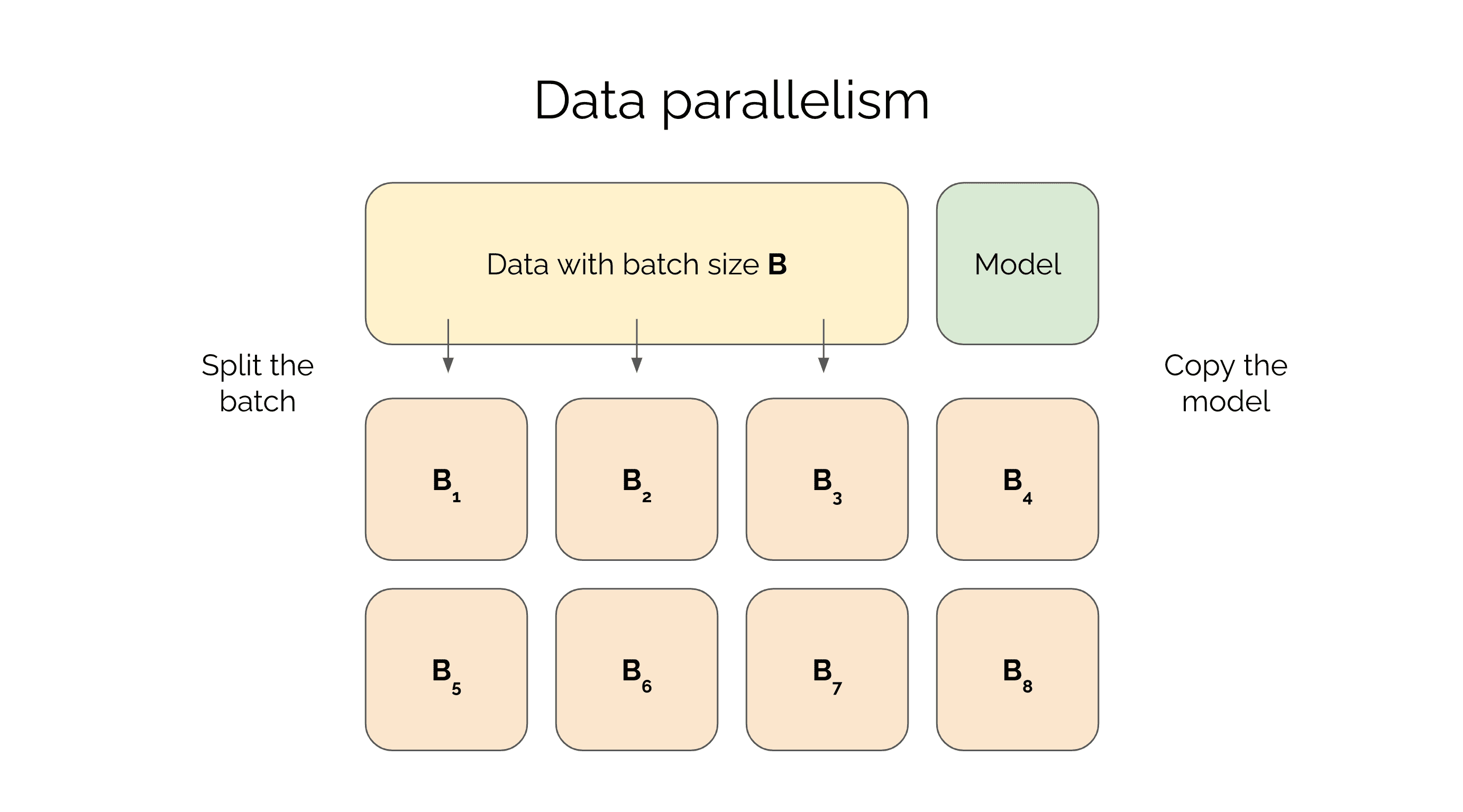
Training Deep Networks with Data Parallelism in Jax
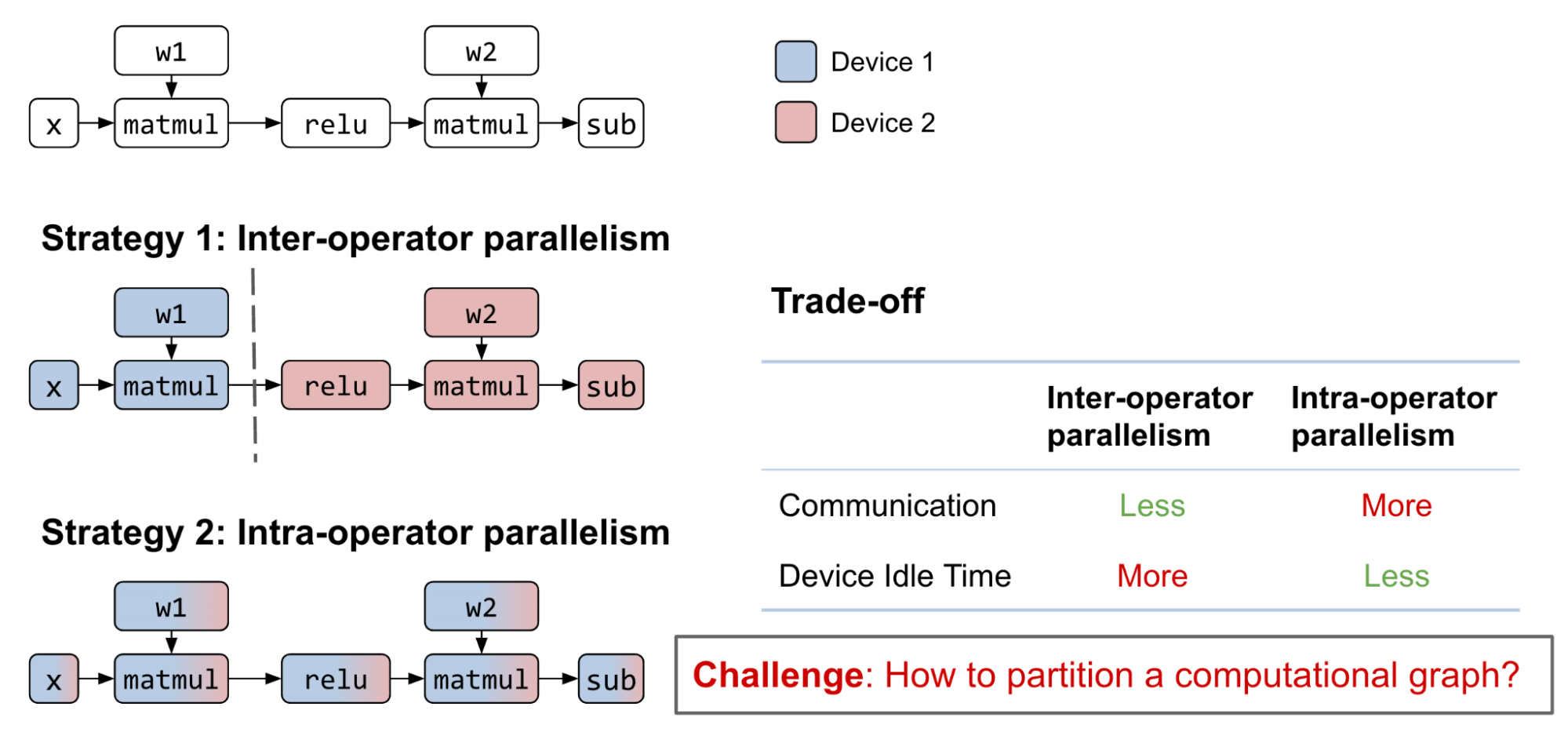
Efficiently Scale LLM Training Across a Large GPU Cluster with

How to train a deep learning model in the cloud
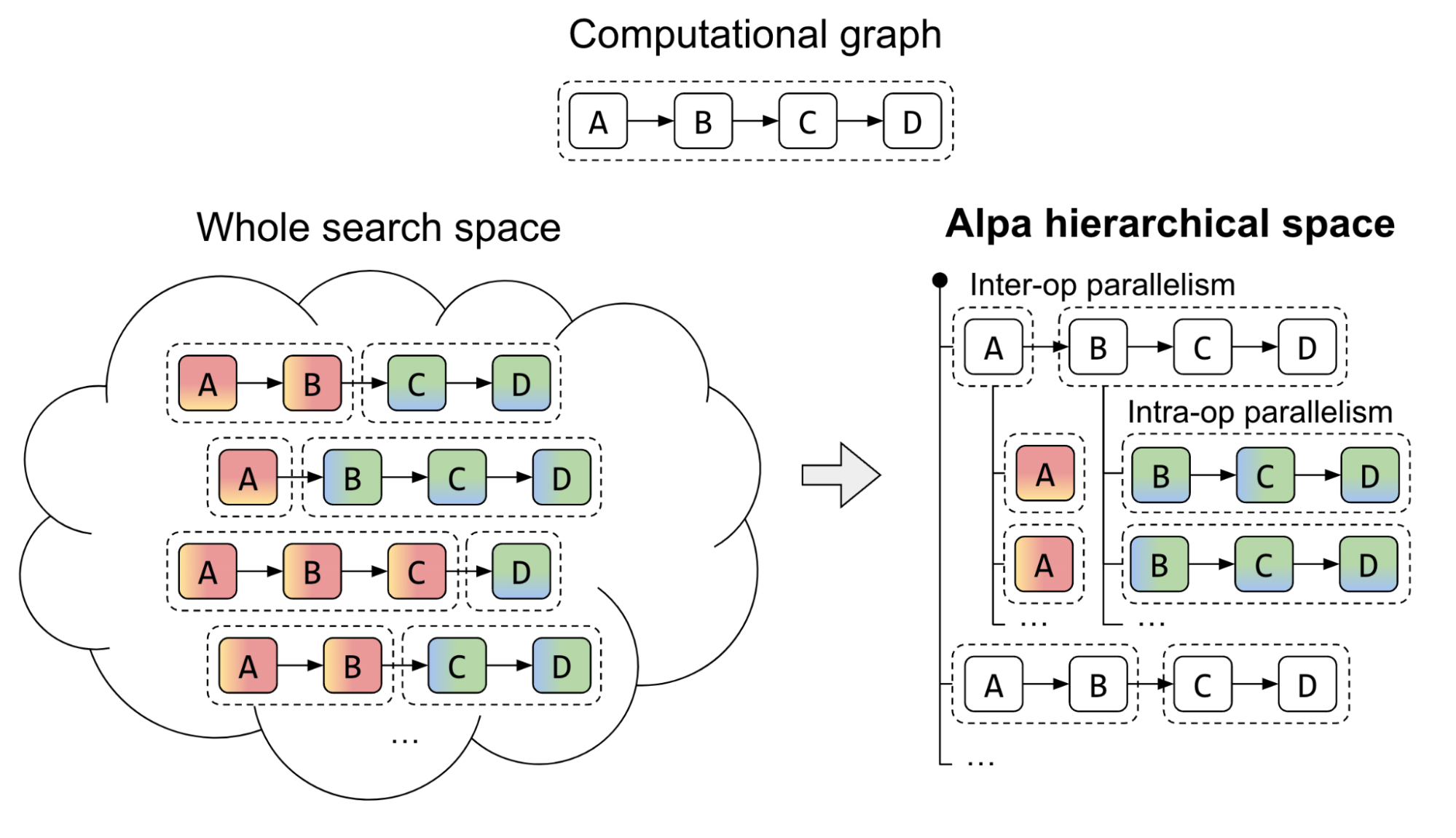
Efficiently Scale LLM Training Across a Large GPU Cluster with
de
por adulto (o preço varia de acordo com o tamanho do grupo)